Edge Detector Dude Released
I’ve written yet another PyGTK application in the near past for the Digital Image Segmentation course of the university.
You ask me what it really is?
Edge Detector Dude is a simple image manipulation application written in Python using PyGTK. It presents you the Sobel edge-detected and the gradient-directed versions of the input image. The pixels of the gradient-directed image is computed by denoting the angle of the gradient of the pixel and mapping this value as a grayscale color.
Edge Detector Dude is more accurately a front end that uses the accompanying gradient utility to process the input image and visualize its result images.
gradient is written in C using the Allegro game programming library.
Let’s see this dude:
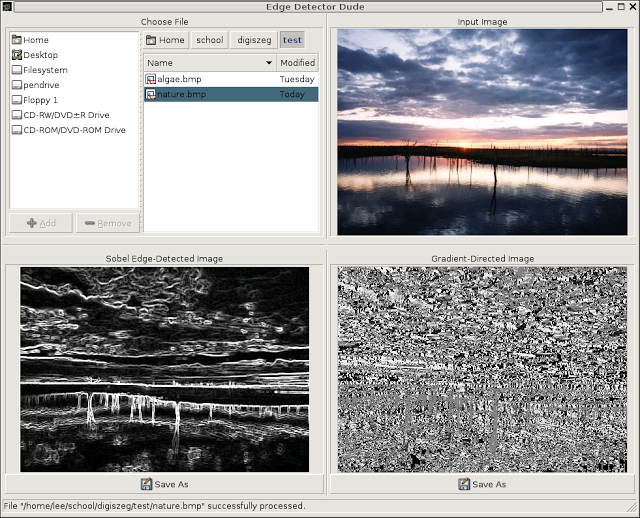
I’m proud of this GUI design because I think it’s very usable, however there are several things that could be improved:
- Add a “View” button to view images. Currently the statausbar mentions that images can be viewed by double clicking on their names, but it’s not very eye-catching and novices may miss it.
- Add support for other file formats. For some strange reason Allegro only handled BMPs, however according to the documentation it should handle a wide variety of image formats.
- Replace the gradient-directed image with something nicer. It’s really ugly, no questions, but I had no choice because that was the exact task to be done.